Model Performance
Infrastructure and Parameters
We used AWS t2.2xlarge instances to test our software. Here is the technical description of the platform:
- CPU model: Intel(R) Xeon(R) CPU E5-2676 v3 @ 2.40GHz
- CPU MHz: 2400.052
- CPU cores: 8
- L1d cache: 32K
- L1i cache: 32K
- L2 cache: 256K
- L3 cache: 30720K
- memory: 32 GiB
- storage: 8 GiB AWS EBS general purpose SSD
- operating system: Ubuntu Server 16.04 LTS (HVM)
We used up to 8 such instances in multi-node tests. The cluster is connected with AWS standard VPC.
To achieve the speedup below, the bootstrapping numbers we used can be found here .
OpenMP Performance
| 16 x 16 Sudoku | 25 x 25 Sudoku |
|
|
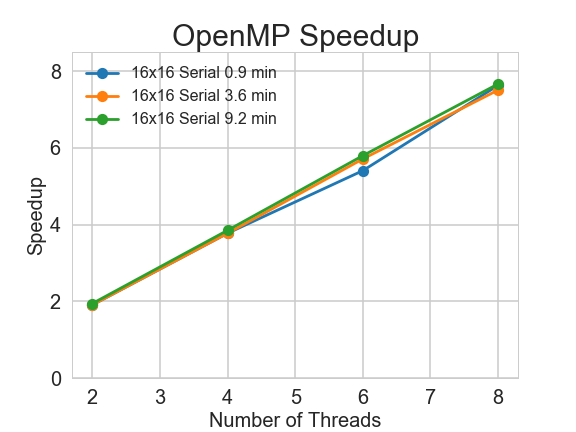
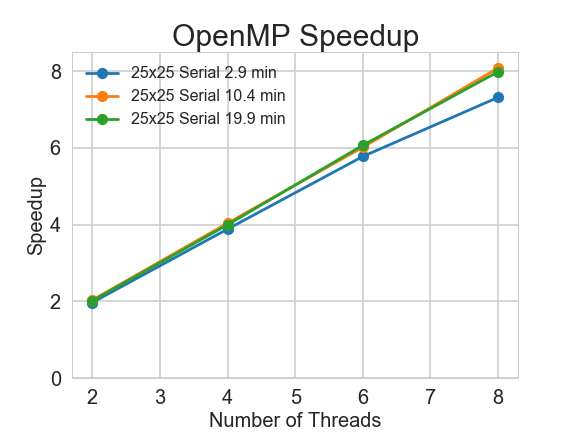
We tested our OpenMP version solver on one AWS t2.2xlarge instance. We experimented with 2, 4, 6 and 8 threads to check its speedup.
Our implementation for the OpenMP version achieves sublinear to linear speedup. Especially for complex Sudoku puzzles, the speedup is linear, which meets our expectation. For easier problems, the speedup is not as good, but still impressive.
MPI + OpenMP Performance
Speedup of Shuffle vs No Shuffle
|
|
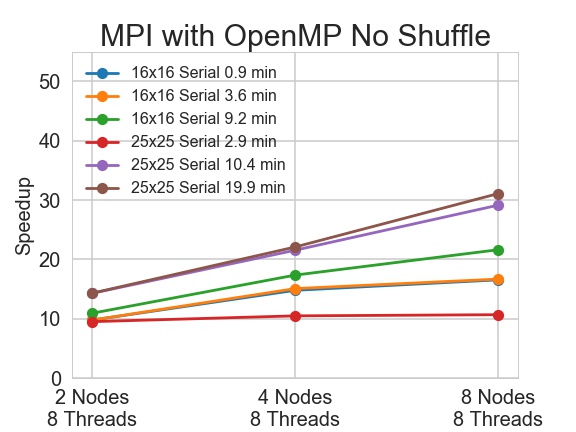
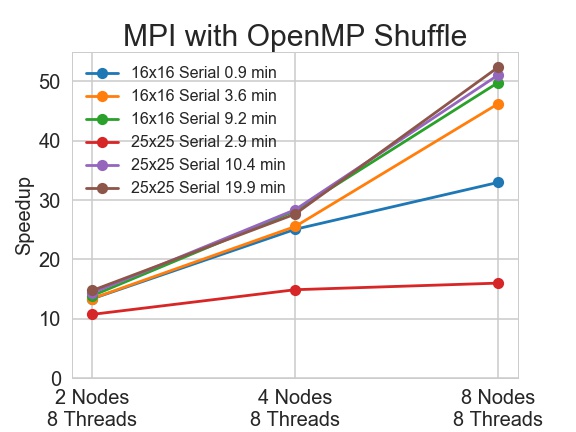
AWS t2.2xlarge instances are used for testing the MPI version. Here we tried 2, 4 and 8 nodes with 8 threads on each node to check the impact of shuffling.
Without shuffling, the speedup of MPI plus OpenMP version varies a lot. We observe high correlation between speedup and problem solving path, we will discuss it in detail in the last section on this page. Shuffling greatly improves the speedup. In the best case scenario, the speedup jumps from 31 to 52.
Effect of Shuffling and Dynamic Scheduling
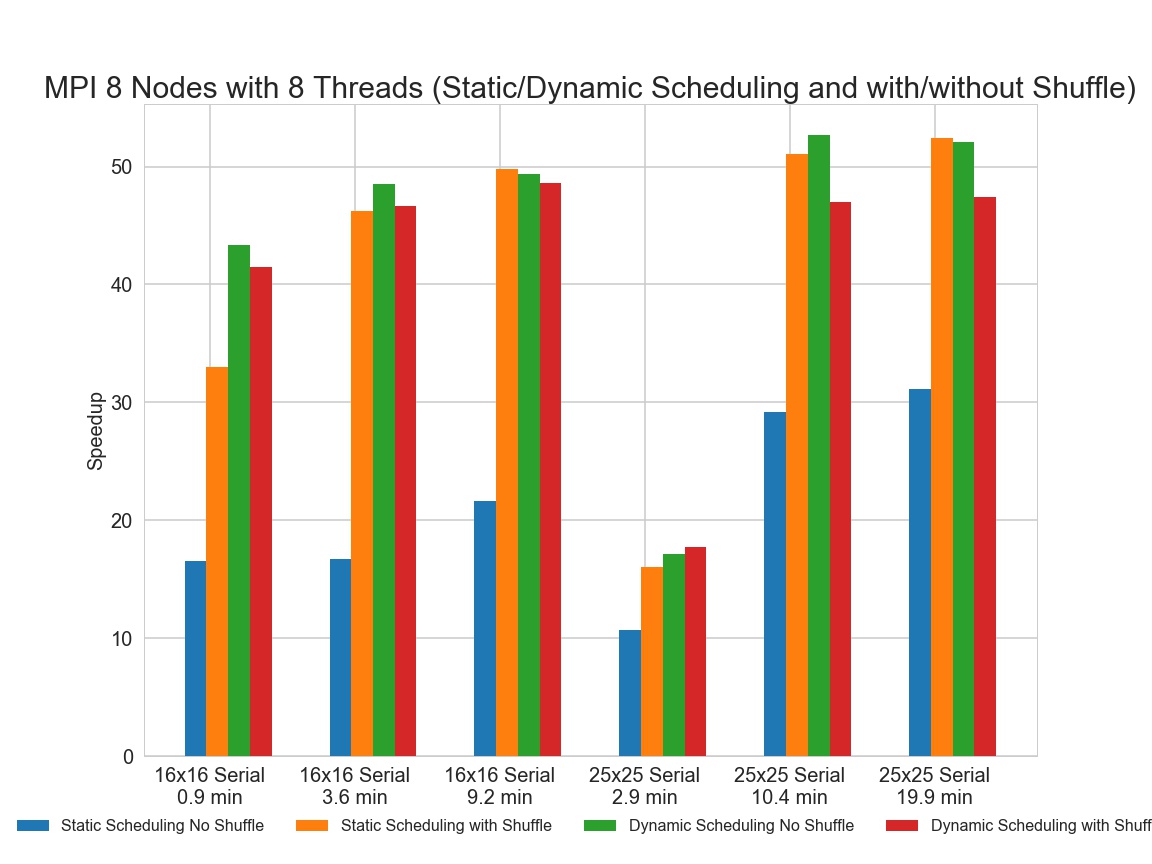
We tested different settings of our MPI+OpenMP version Sudoku solver on 8 AWS t2.2xlarge instances. Each node has 8 threads.
In general, we observed that dynamic scheduling without shuffling yields the highest speedup. Dynamic scheduling with shuffling is better than static scheduling with shuffling for simpler problems. Static scheduling with shuffling tends to perform well for complex problems.
Discussion
Our serial solver guarantees to find a solution but is very slow in terms of the execution time. Achieving good speedup will help us to find solutions in a much shorter amount of time. The main difficulty in parallelizing the Sudoku solver is balancing the workload assigned to each worker. Our bootstrapping methods tends to push partially filled boards with similar solving complexity to adjacent places in the queue. Therefore, it is very likely that some worker will finish the work faster than the others and becomes idle, which jeopardizes the performance of our parallelized solver. OpenMP can do load balancing rather easily by setting the running schedule to dynamic. However, MPI does not have such functionality as a built-in. In order to achieve similar effect, we first attempted to shuffle the queue of boards before dispatching to each worker node. It greatly improves the performance but the speedup is still not ideal. We then implemented dynamic scheduling for the MPI version by sacrificing our master node to constantly query the status of slave nodes. The master node will assign new jobs to the slave nodes once it becomes idle. As you can see on the plot above, MPI dynamic scheduling produces the best performance. Please do not forget that essentially only 7 nodes are working in the dynamic scheduling case. It is very impressive that dynamic scheduling can outperform the other settings. The speedup is not linear mostly due to the high communication costs between the nodes. Adding shuffling to MPI dynamic scheduling slows our parallelized solver. The main reason is that shuffling and dynamic scheduling have similar functionalities. Dynamic scheduling already solved the problem of load balancing, and shuffling cannot do more. Furthermore, it takes time to shuffle the queue, and the shuffling can only be done in serial.